Jobs
Jobs are nothing but long running services. Job is also a groovy script and all the applicable context libraries similar to rules engine script is also available for a job. unlike rules engine scripts, jobs can be configured in four different ways in the platform.
Every job doesn't have to run indefinitely, you can create jobs and start them on the fly, once your task is done, you could exit the job to give computing cycles for other processes.
Communication between your rule scripts and jobs are made simple, you could use distributed data structures to send and receive data internally within the cluster. See Grid and Global Grid for more information.
Let's say you want to do some complex mathematical computation on every 1000 datasets you gather from your devices and you want the computation to happen in 4 parallel threads, in this scenario, you could check for the number of job instances running on the fly and start only the needed instances. You can find out more here
Job Types
Jobs can be created very similar to creating other types of rules. Home -> Rules Engine -> Job Rule (Dropdown).
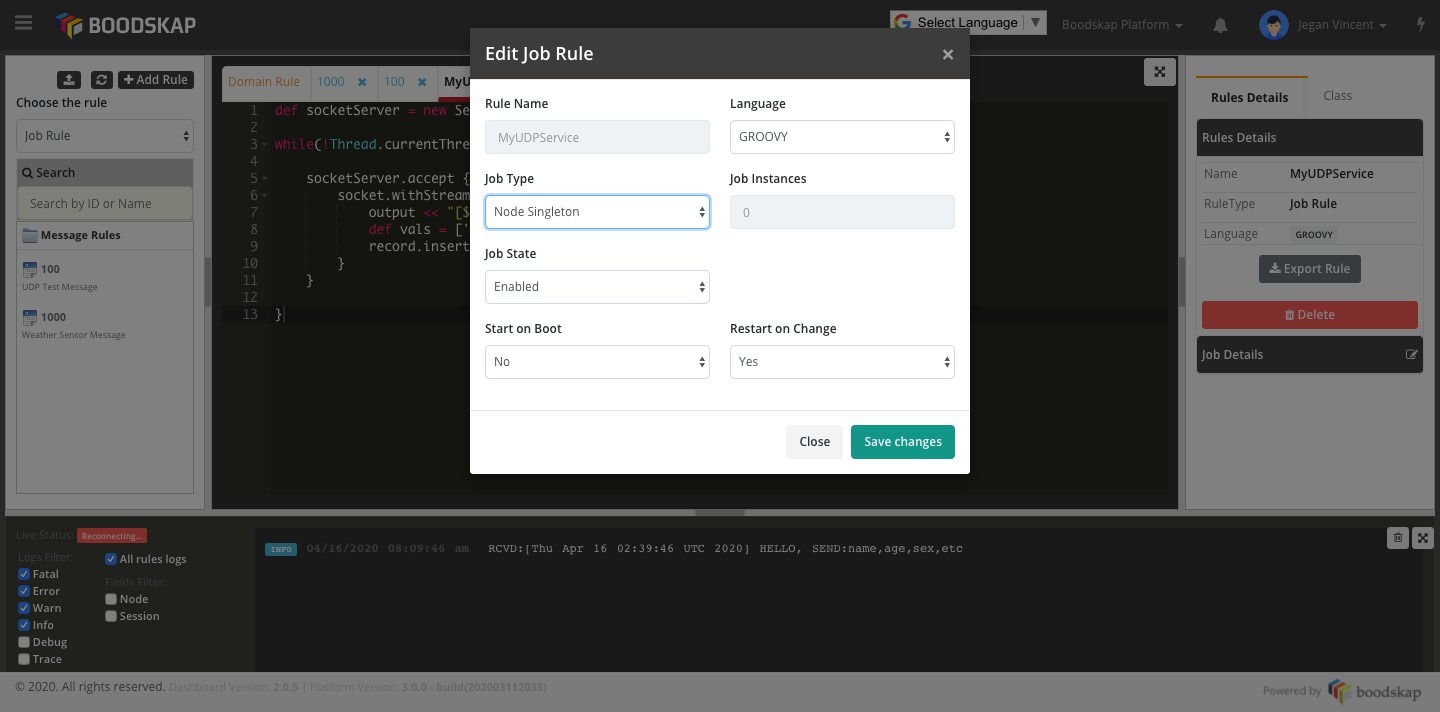
Example: Simple Indefinitely Running Job
A simple UDP service to receive packets and store into a record
def socketServer = new ServerSocket(5000)
while(!Thread.currentThread().isInterrupted()) {
socketServer.accept { socket ->
socket.withStreams { input, output ->
output << "[${new Date()}] HELLO\n"
def vals = ['data': input.newReader().readLine()];
record.insert(4000, vals);
}
}
}Related REST APIs
[Create / Update Job(ref:upsertjob)
Get Job
Delete Job
Count Jobs
List Jobs
Set Job State
Count Running Jobs
List Running Jobs
Start Job
Restart Job
Count All Running Jobs
Updated about 1 year ago